
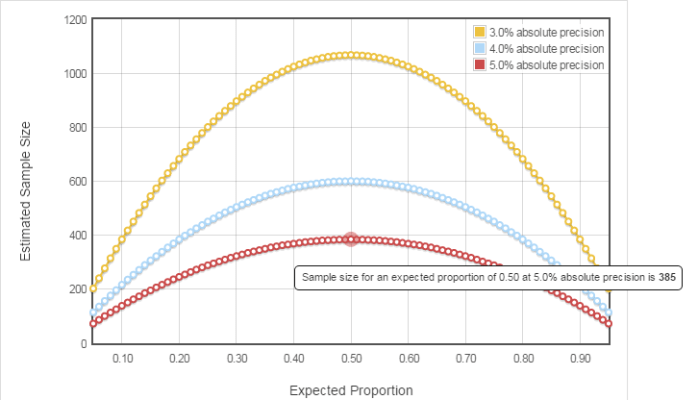
Training@Staburo: Guideline for sample size calculations at Staburo
 The presentation was about the current guideline for sample size calculations that is in place at Staburo. This guideline has been presented to the whole team and is intended to help everybody, when performing such calculations in his/her projects.
The presentation was about the current guideline for sample size calculations that is in place at Staburo. This guideline has been presented to the whole team and is intended to help everybody, when performing such calculations in his/her projects.
The first version of this guideline has been finalised and contains already some settings (such as evaluations with binary or time-to-event endpoints). However, the objective is that all colleagues get involved and share their experience (different types of trial settings/designs, of endpoints). Indeed, each project has its own specifics, each colleague has his/her own expertise areas and is therefore able to contribute to improve the guideline. On the other side, this guideline will help in new projects with similar questions as previous ones, since it gathers earlier experience.
Ideally, each setting contains the following parts: assumptions and methodology used with corresponding references, example of program doing the calculation (using SAS or other adapted), and template text for protocol.
As a conclusion, this guideline will bring benefit to new projects and further improve the quality of our handling of customers‘ requests!
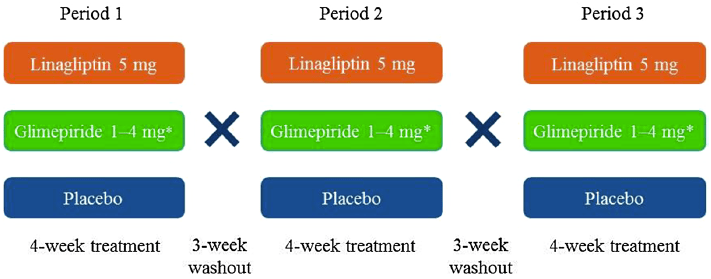
 Another publication with Staburo biostatistics support, this time in diabetes type 2.
Another publication with Staburo biostatistics support, this time in diabetes type 2.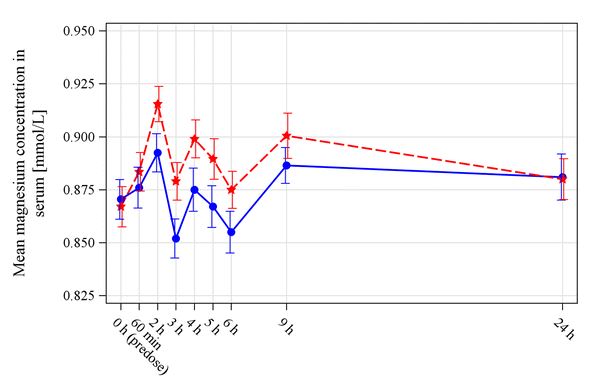
 Staburo delivered biostatistics services in this bioavailability study.
Staburo delivered biostatistics services in this bioavailability study.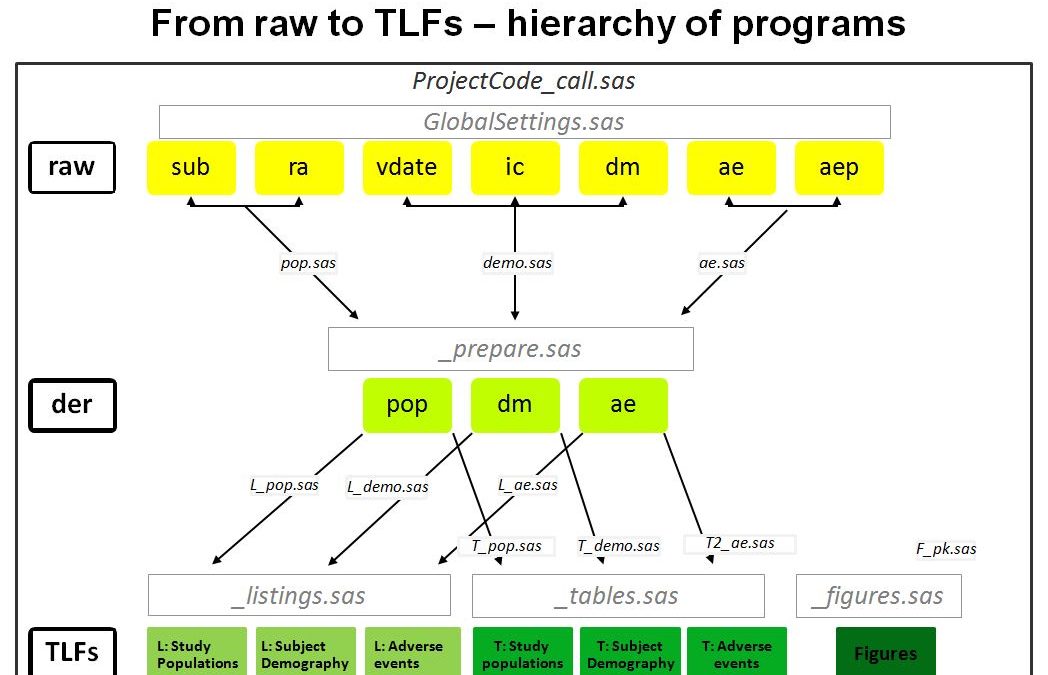
 The Staburo SAS programming environment facilitates the creation of meaningful outputs, such as tables, listings and figures (TLFs), from client supplied data.
The Staburo SAS programming environment facilitates the creation of meaningful outputs, such as tables, listings and figures (TLFs), from client supplied data.
 We wish all our partners and future partners, all our employees and future employees, and all their families a wonderful Christmas and a great start in 2017. Staburo will continue to support you with experienced biostatisticians and statistical programmers next year and in the years to come!
We wish all our partners and future partners, all our employees and future employees, and all their families a wonderful Christmas and a great start in 2017. Staburo will continue to support you with experienced biostatisticians and statistical programmers next year and in the years to come!
Recent Comments